About
About Our Project
Our project is based around a fictional dataset that gave us various details on employees and whether they attrited or not. The challenge was to incorporate machine learning to give us an algorithm, for a company or manager to use, that determines if an employee will leave their position. Unfortunately, this data does not allow the creation of a model that can predict when an employee will leave but rather show you the likelihood of resignation in that current moment based on specific variables. From the dataset, we were given ratings for each employee on the below factors:
- Education
- Environment Satisfaction
- Job Involvement
- Job Satisfaction
- Performance Rating
- Relationship Satisfaction
- Work Life Balance
Education was ranked 1-5, 1 being "Below College" and 5 being "Doctor." Environment Satisfaction was ranked 1-4; "Low" to "Very High." Job Involvement, Job Satisfaction, Performance Rating, Relationship Satisfaction, Work Life Balance all had similar 1-4 rankings, with 1 being "Low" and 4 being "Very High/Outstanding."
Other more straight-forward data points we were given were Age, Gender, Marital Status, Job Title, Travel Time and Years Spent in Position. Most importantly, we were also given each employees Monthly Income and a Yes/No of whether they attrited or not.

Summary
Project Summary
Data Exploration & Cleanup
Our dataset came from a Kaggle project called IBM HR Analytics Employee Attrition & Performance. The .csv file contains 35 categories of employee data and 1,470 lines of data. Of the 1,470 employees, the average age is 37 (the oldest being 60). $6,502 is the average monthly income with $1,009 at the lower end and $19,999 as the greatest salary. The average years spent in a position is 11.3 (40 years as the longest). Of all the employees, 237 left the company.
Machine Learning
We used scikit-learn, a Machine Learning library in Python, to train, test and split the data. We tested the following models: Linear Regression, Lasso, Ridge, ElasticNet, Decision Tree Classifier, Random Forest, Gradient Boosting.
Visualizations
We used tableau, a visual analytics software, to create 22 visualizations based on employee attrition. Multiple variables were analyzed including travel frequency, job role, education field, overtime, marital status, age, education level, environment satisfaction and performance rating. Click here to view all the visualizations created for this data set.
Web Design
We used this multi purpose Bootstrap template to create a web design to present our project. We modified the HTML and CSS to align with our data story.



Visualizations
Project Visualizations
and in
Conclusion
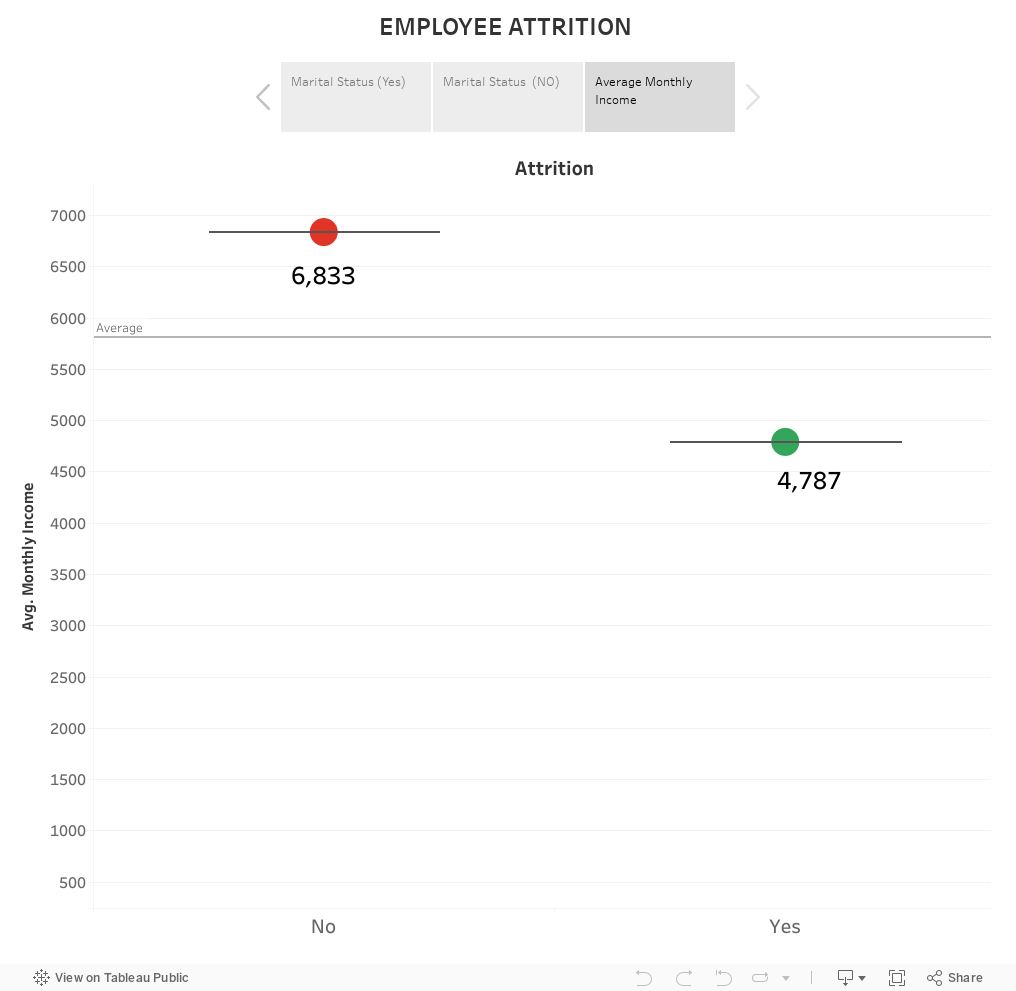
In our review of the data and in our visualizations within Tableau, you can see that there is no single variable which determines attrition rates. There are a few tendencies which become apparent in the data. For example, more single people are at risk of attrition than married people and the average monthly income of those who leave the company is lower than the overall company average. These examples are specific to our dataset, and therefore we needed a model which could be sensitive to them.
Machine learning techniques also confirmed this by showing a very broad importance value range for many different variables. We used the Gradient Booster model for this dataset due to its unique approach to correcting for overfit in complex questions such as this one. Our Gradient Boosting Model enables us to use the outliers to predict using all of the measured variables and correcting as the algorithm runs. While there is no one factor which determines attrition, we can use this model to identify those factors which may make attrition more likely. This means, that now that we have trained this model, we can use similar data to determine the likelihood of attrition for any particular individual. Additionally, we could create a similar model for attrition data in another industry which may have different influential factors.
Team
Check Out Our Team

Shawn Boehm
Data Analyst
Annii Cope
Data Analyst
Michelle Hannah
Data Analyst
Emily Keymon
Data Analyst